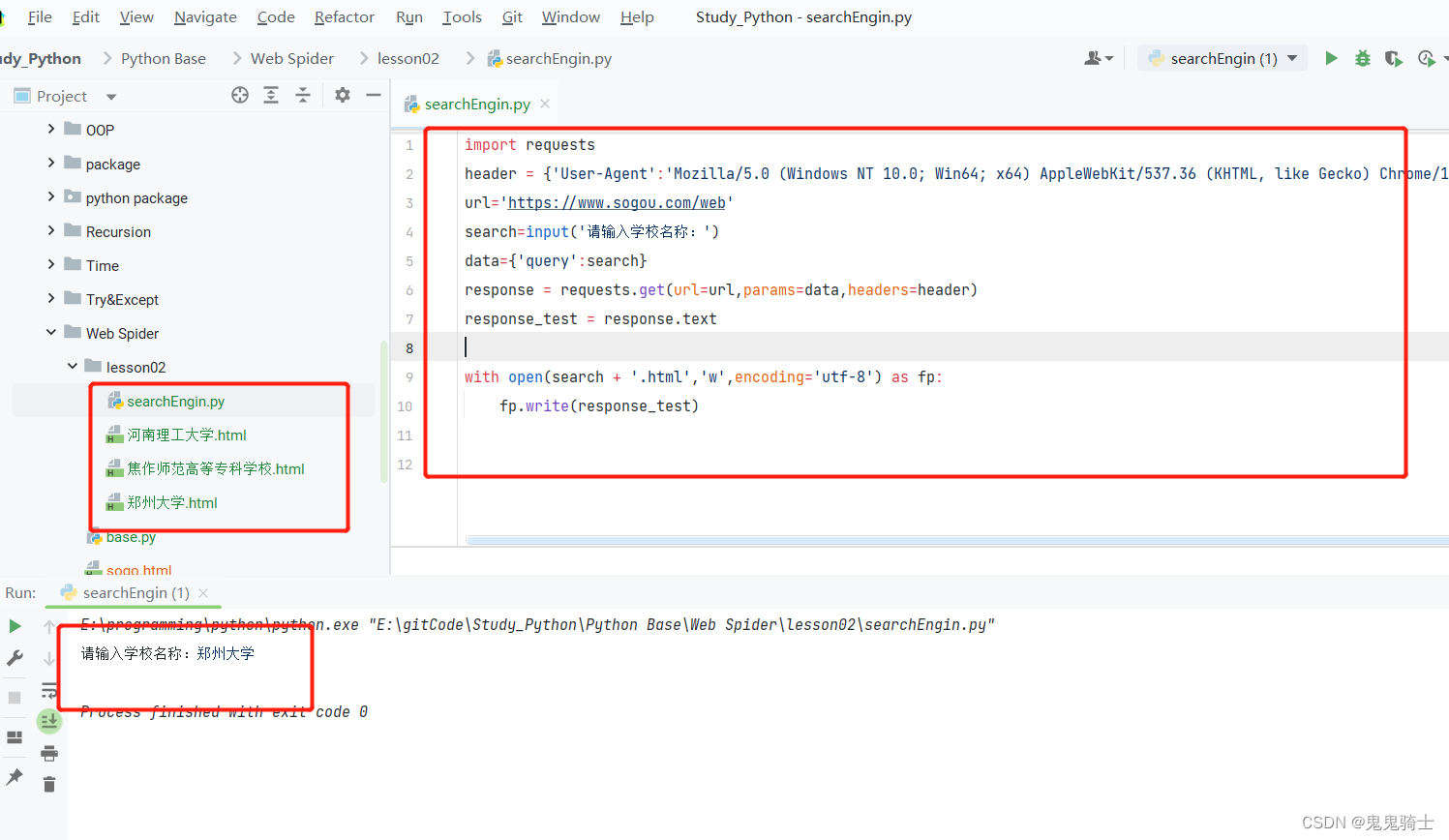
import requests
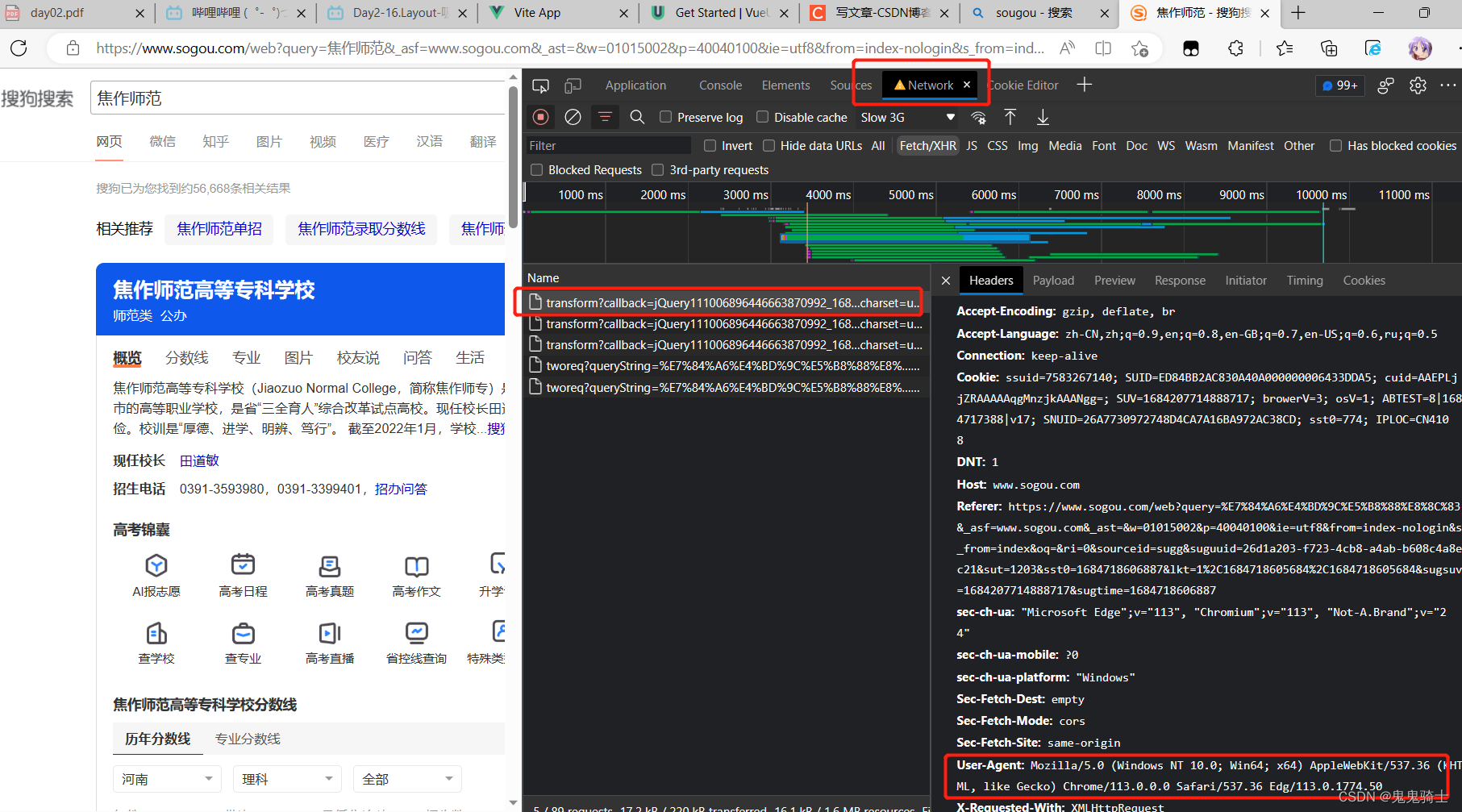
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50'}
url='https://www.sogou.com/web'
search=input('请输入学校名称')
data={'query':search}
response = requests.get(url=url,params=data,headers=header)
response_test = response.text
with open(search + '.html','w',encoding='utf-8') as fp:
fp.write(response_test)
 热门活动
大客户专属客服
热门活动
大客户专属客服
 联系我们
联系我们
客服时间
09:00 - 22:30(工作日)
10:30 - 22:30(非工作日)

电话咨询
13372284888

QQ咨询
1792779638

微信客服
添加微信沟通咨询









